Le monde de l’intelligence artificielle générative évolue à une vitesse fulgurante. L’accès aux large language models (LLMs), autrefois réservé aux professionnels et aux entreprises disposant de ressources considérables, se démocratise. Désormais, grâce aux avancées technologiques et aux optimisations logicielles, il est possible d’exécuter des LLMs performants directement sur son propre ordinateur, offrant ainsi une confidentialité accrue et un contrôle total sur ses données. Cette révolution ouvre des perspectives inédites pour les étudiants, les passionnés et les développeurs, qui peuvent désormais explorer les applications de l’IA générative localement.
NVIDIA, en collaboration avec la communauté open source, est au cœur de cette transformation. La société a optimisé ses cartes graphiques RTX pour accélérer l’exécution des LLMs, rendant l’expérience utilisateur plus fluide et réactive. Cet article explore les différentes façons de se lancer dans l’aventure des LLMs sur PC, en mettant l’accent sur les outils et les technologies qui facilitent cette transition. Que vous soyez novice ou expert, vous découvrirez comment tirer parti de la puissance de votre RTX pour générer du texte, répondre à des questions, créer du contenu et bien plus encore.
Démarrer avec les LLMs locaux optimisés pour les PC RTX
L’une des approches les plus simples pour expérimenter l’IA sur PC consiste à utiliser Ollama Ollama, un outil open-source qui offre une interface conviviale pour exécuter et interagir avec différents LLMs. Ollama prend en charge l’importation de fichiers PDF, les conversations interactives et les workflows multimodaux intégrant texte et images. NVIDIA a collaboré avec Ollama pour améliorer ses performances et l’expérience utilisateur. Parmi les développements récents, on note des améliorations significatives sur les GPU GeForce RTX pour le modèle gpt-oss-20B de OpenAI et les modèles Gemma 3 de Google. De plus, Ollama prend désormais en charge les nouveaux modèles Gemma 3 270M et EmbeddingGemma3 pour une génération augmentée par récupération (RAG) hyper-efficace sur les PC RTX AI. On observe également une amélioration du système de planification des modèles pour maximiser et signaler avec précision l’utilisation de la mémoire, ainsi que des améliorations en matière de stabilité et de prise en charge multi-GPU.
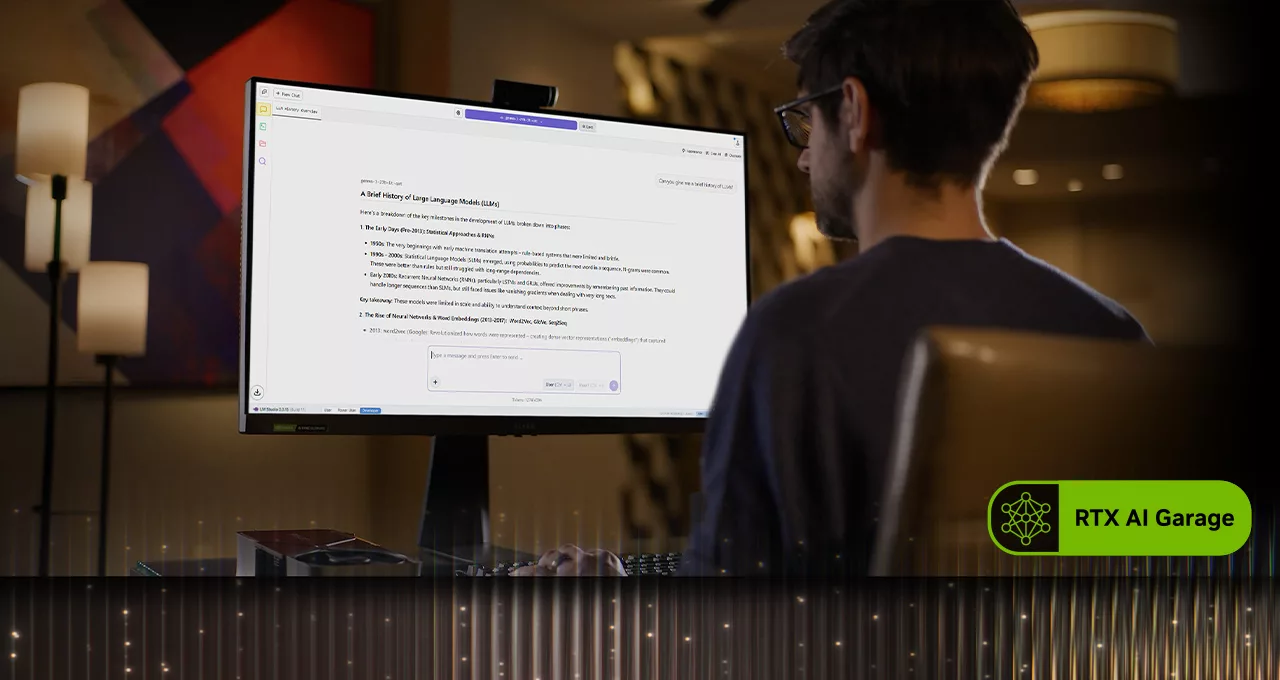
Les passionnés peuvent également explorer les LLMs locaux en utilisant LM Studio LM Studio, une application basée sur le framework populaire llama.cpp. LM Studio propose une interface utilisateur intuitive pour exécuter des modèles localement, permettant aux utilisateurs de charger différents LLMs, de discuter avec eux en temps réel et même de les servir en tant que points de terminaison d’interface de programmation d’applications (API) locaux pour une intégration dans des projets personnalisés. NVIDIA a travaillé avec llama.cpp pour optimiser les performances sur les GPU NVIDIA RTX. Les dernières mises à jour incluent la prise en charge du dernier modèle NVIDIA Nemotron Nano v2 9B NVIDIA Nemotron Nano v2 9B model, basé sur la nouvelle architecture hybride-mamba, l’activation par défaut de Flash Attention, offrant jusqu’à 20 % d’amélioration des performances, et des optimisations des noyaux CUDA pour RMS Norm et modulo basé sur fast-div, ce qui se traduit par jusqu’à 9 % d’amélioration des performances pour les modèles populaires.
Créer un tuteur d’étude alimenté par l’IA avec AnythingLLM
Au-delà de la confidentialité et des performances accrues, l’exécution de LLMs localement élimine les restrictions sur le nombre de fichiers pouvant être chargés ou la durée pendant laquelle ils restent disponibles, ce qui permet des conversations IA contextuelles pendant une période plus longue. Cela ouvre des possibilités pour la création d’assistants conversationnels et génératifs alimentés par l’IA. Pour les étudiants, la gestion d’une multitude de diapositives, de notes, de travaux pratiques et d’examens passés peut être accablante. Les LLMs locaux permettent de créer un tuteur personnel qui peut s’adapter aux besoins d’apprentissage individuels. AnythingLLM est un outil simple qui prend en charge les téléchargements de documents, les bases de connaissances personnalisées et les interfaces conversationnelles. Cela en fait un outil flexible pour toute personne souhaitant créer une IA personnalisable pour l’aider dans ses recherches, ses projets ou ses tâches quotidiennes. Avec l’accélération RTX, les utilisateurs peuvent bénéficier de réponses encore plus rapides.
En chargeant des programmes, des devoirs et des manuels scolaires dans AnythingLLM sur les PC RTX, les étudiants peuvent obtenir un compagnon d’étude interactif et adaptatif. Ils peuvent demander à l’agent, en utilisant du texte brut ou la parole, de les aider avec des tâches telles que la génération de flashcards à partir de diapositives de cours, la réponse à des questions contextuelles liées à leurs documents ou la création et la notation de quiz pour la préparation aux examens. Au-delà de la salle de classe, les amateurs et les professionnels peuvent utiliser AnythingLLM pour se préparer à des certifications dans de nouveaux domaines d’études ou à d’autres fins similaires. L’exécution locale sur les GPU RTX garantit des réponses rapides et privées, sans frais d’abonnement ni limites d’utilisation.
Project G-Assist : Contrôle des paramètres de l’ordinateur portable
NVIDIA ne se limite pas à l’accélération des LLMs ; elle développe également des outils pour faciliter l’interaction avec ces modèles. Project G-Assist, un assistant expérimental basé sur l’IA, permet aux utilisateurs de régler, de contrôler et d’optimiser leurs PC de jeu via des commandes vocales ou textuelles simples, sans avoir à naviguer dans des menus complexes. Avec la nouvelle mise à jour, G-Assist ajoute des commandes pour ajuster les paramètres de l’ordinateur portable, notamment des profils d’applications optimisés pour les ordinateurs portables, le contrôle de BatteryBoost et le contrôle de WhisperMode. Project G-Assist est également extensible. Avec le G-Assist Plug-In Builder, les utilisateurs peuvent créer et personnaliser les fonctionnalités de G-Assist en ajoutant de nouvelles commandes ou en connectant des outils externes avec des plug-ins faciles à créer. Avec le G-Assist Plug-In Hub, les utilisateurs peuvent facilement découvrir et installer des plug-ins pour étendre les capacités de G-Assist.
N’oubliez pas de consulter le dépôt GitHub de NVIDIA G-Assist pour obtenir des informations sur la façon de démarrer, y compris des exemples de plug-ins, des instructions étape par étape et de la documentation pour la création de fonctionnalités personnalisées. La prise en charge des large language models (LLMs) [large language models (LLMs)] sur les PC RTX ouvre de nouvelles portes pour l’IA, en offrant aux utilisateurs un contrôle sans précédent sur leurs données et leurs expériences. Avec les outils et les optimisations fournis par NVIDIA et la communauté open source, il n’a jamais été aussi facile de se lancer dans cette révolution.
Perspectives d’avenir
L’avenir des LLMs sur PC RTX est prometteur. Les améliorations continues des performances, la prise en charge de nouveaux modèles et le développement d’outils conviviaux rendent l’accès à l’IA générative plus facile que jamais. NVIDIA continue d’investir massivement dans ce domaine, en optimisant les GPU RTX pour les LLMs et en collaborant avec la communauté open source pour proposer des solutions innovantes. L’accent mis sur la confidentialité et le contrôle des données est un atout majeur, qui permet aux utilisateurs de tirer pleinement parti des capacités de l’IA sans compromettre leur vie privée.
Les possibilités sont infinies, allant de l’amélioration de l’apprentissage et de la productivité à la création de nouveaux types d’applications et de services. Que vous soyez un étudiant, un développeur ou un passionné de technologie, il n’y a jamais eu de meilleur moment pour explorer le monde des LLMs sur votre PC RTX. En vous informant sur les dernières avancées et en expérimentant les outils disponibles, vous pouvez contribuer à façonner l’avenir de l’IA.