La révolution de l’IA générative : le « RAG » à la rescousse
Imaginez un tribunal où les juges prennent des décisions en se basant sur leur compréhension générale de la loi. Parfois, une affaire nécessite une expertise particulière, comme un procès pour faute professionnelle ou un conflit de travail. Les juges envoient alors des greffiers consulter des bibliothèques juridiques à la recherche de précédents et de cas spécifiques qu’ils pourront citer.
À l’instar d’un bon juge, les grands modèles de langage (LLM) peuvent répondre à une grande variété de questions humaines. Mais pour fournir des réponses faisant autorité – fondées sur des procédures judiciaires spécifiques ou similaires – le modèle doit disposer de ces informations.

Le « RAG » : le greffier de l’IA
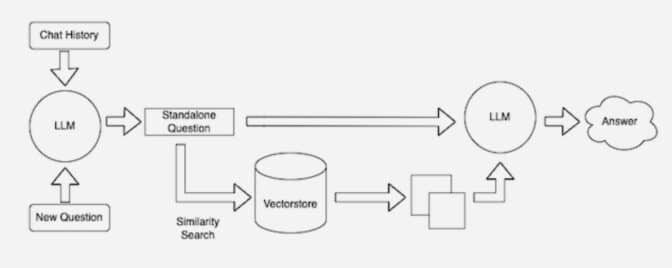
Le greffier de l’IA est un processus appelé « Retrieval-Augmented Generation » (RAG).
Patrick Lewis, auteur principal de l’article de 2020 qui a inventé le terme, s’est excusé pour l’acronyme peu flatteur qui décrit désormais une famille croissante de méthodes utilisées dans des centaines d’articles et des dizaines de services commerciaux. Il estime que ces méthodes représentent l’avenir de l’IA générative.
« Nous aurions certainement réfléchi davantage au nom si nous avions su que notre travail deviendrait aussi répandu », a déclaré Lewis lors d’une interview depuis Singapour, où il partageait ses idées avec une conférence régionale de développeurs de bases de données.
Qu’est-ce que le « RAG » ?
Le « Retrieval-Augmented Generation » est une technique qui améliore la précision et la fiabilité des modèles d’IA générative grâce à des informations provenant de sources de données spécifiques et pertinentes.
En d’autres termes, il comble une lacune dans le fonctionnement des LLM. Sous le capot, les LLM sont des réseaux neuronaux, généralement mesurés par le nombre de paramètres qu’ils contiennent. Les paramètres d’un LLM représentent essentiellement les schémas généraux de la façon dont les humains utilisent les mots pour former des phrases.
Cette compréhension approfondie, parfois appelée connaissances paramétrées, rend les LLM utiles pour répondre à des invites générales. Cependant, elle ne sert pas les utilisateurs qui souhaitent approfondir un type d’information spécifique.
Combiner les ressources internes et externes
Lewis et ses collègues ont développé le RAG pour relier les services d’IA générative à des ressources externes, en particulier celles riches en détails techniques.
L’article, rédigé en collaboration avec d’anciens chercheurs de Facebook AI Research (désormais Meta AI), de l’University College London et de l’Université de New York, qualifie le RAG de « recette universelle d’ajustement fin » car il peut être utilisé par presque n’importe quel LLM pour se connecter à pratiquement n’importe quelle ressource externe.
Renforcer la confiance des utilisateurs
Le RAG fournit aux modèles des sources qu’ils peuvent citer, comme des notes de bas de page dans un article de recherche, afin que les utilisateurs puissent vérifier toute affirmation. Cela renforce la confiance.
De plus, cette technique peut aider les modèles à clarifier les ambiguïtés dans une requête utilisateur. Elle réduit également la possibilité qu’un modèle donne une réponse très plausible mais incorrecte, un phénomène appelé « hallucination ».
Un autre avantage majeur du RAG est sa relative simplicité.
Selon un article de blog de Lewis et de trois des coauteurs de l’article, les développeurs peuvent mettre en œuvre le processus avec seulement cinq lignes de code.
Cela rend la méthode plus rapide et moins coûteuse que le recyclage d’un modèle avec des ensembles de données supplémentaires. Et cela permet aux utilisateurs d’intervertir des nouvelles sources à la volée.
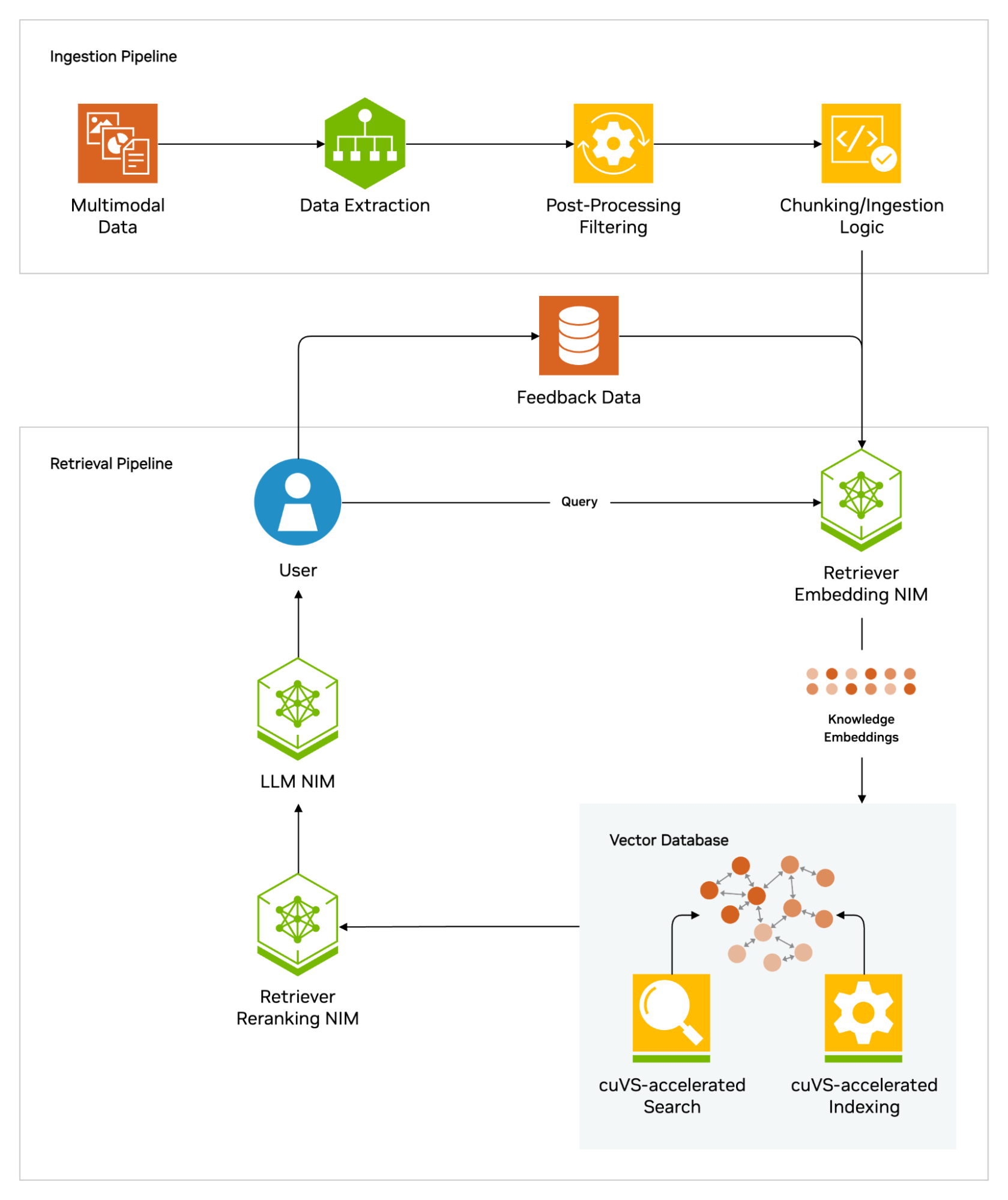
Les applications du RAG
Avec le RAG, les utilisateurs peuvent essentiellement avoir des conversations avec des référentiels de données, ce qui ouvre de nouveaux types d’expériences. Cela signifie que les applications du RAG pourraient être plusieurs fois supérieures au nombre de jeux de données disponibles.
Par exemple, un modèle d’IA générative complété par un index médical pourrait être un excellent assistant pour un médecin ou une infirmière. Les analystes financiers bénéficieraient d’un assistant lié aux données de marché.
En fait, presque toutes les entreprises peuvent transformer leurs manuels techniques ou politiques, leurs vidéos ou leurs journaux en ressources appelées bases de connaissances qui peuvent améliorer les LLM. Ces sources peuvent permettre des cas d’utilisation tels que l’assistance client ou sur le terrain, la formation des employés et la productivité des développeurs.

C’est pourquoi des entreprises telles qu’AWS, IBM, Glean, Google, Microsoft, NVIDIA, Oracle et Pinecone adoptent le RAG.
Conclusion : vers un avenir de l’IA générative assistée
Le RAG ne nécessite pas de centre de données. Les LLM font leurs débuts sur les PC Windows, grâce au logiciel NVIDIA qui permet toutes sortes d’applications auxquelles les utilisateurs peuvent accéder même sur leurs ordinateurs portables.
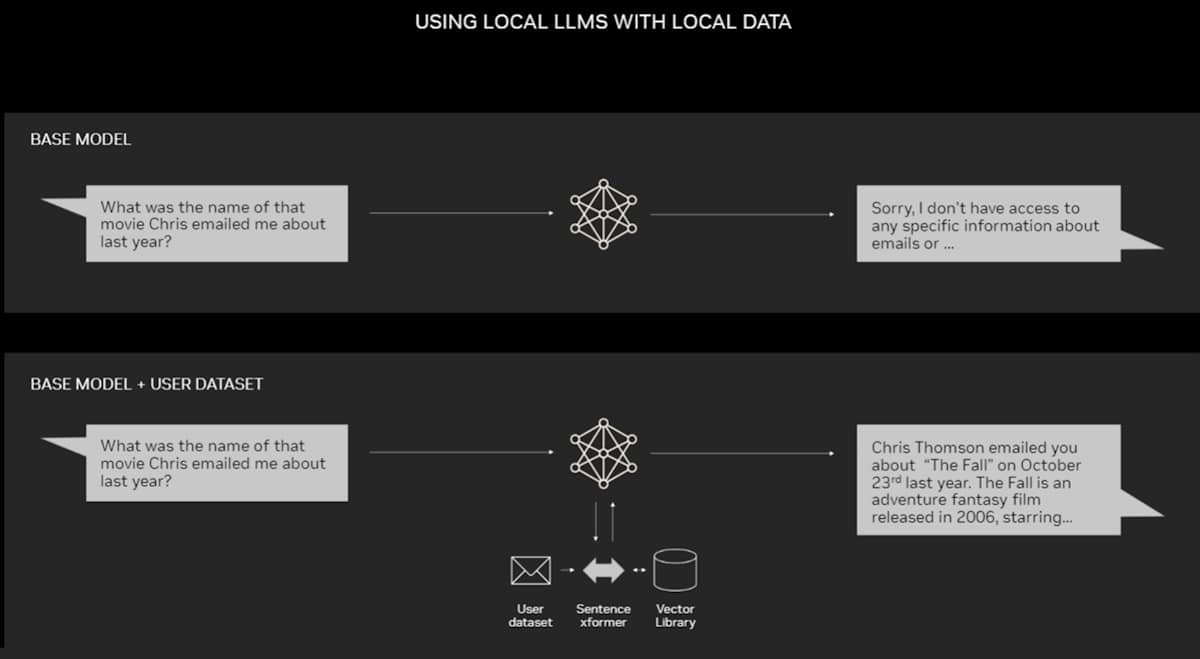
Les PC équipés de GPU NVIDIA RTX peuvent désormais exécuter certains modèles d’IA localement. En utilisant le RAG sur un PC, les utilisateurs peuvent se connecter à une source de connaissances privée – que ce soit des e-mails, des notes ou des articles – pour améliorer les réponses. L’utilisateur peut alors être sûr que sa source de données, ses invites et sa réponse restent tous privés et sécurisés.
L’avenir de l’IA générative réside dans l’IA agentique, où les LLM et les bases de connaissances sont orchestrés de manière dynamique pour créer des assistants autonomes. Ces agents pilotés par l’IA peuvent améliorer la prise de décision, s’adapter à des tâches complexes et fournir des résultats faisant autorité et vérifiables pour les utilisateurs.